P1 रिपोर्ट की व्याख्या — घूर्णन वक्रों से कमज़ोर लेंसिंग तक: EFT की औसत गुरुत्वीय प्रतिक्रिया की जाँच कैसे करें
《P1_RC_GGL: आकाशगंगा गतिकी और कमज़ोर लेंसिंग का कठोर क्लोज़र परीक्षण (v1.1)》 पर आधारित सार्वजनिक व्याख्या संस्करण
मूल मूल्यांकन रिपोर्ट देखें:
1. ChatGPT: https://chatgpt.com/share/6a00cd62-6e34-83eb-b165-6ec09e3519cc
2. Gemini: https://gemini.google.com/share/773ec96d75a0
3. Grok: https://grok.com/share/bGVnYWN5LWNvcHk_c0b4fa65-0e86-4adb-9b58-5617d616dc04
4. Qwen: https://chat.qwen.ai/s/22ab9336-671f-420a-a7fa-43e24774bb2a?fev=0.2.46
5. DeepSeek: https://chat.deepseek.com/share/tj6k7hb5owtoldg2bm
पठन नोट |
यह एक “व्याख्यात्मक संस्करण” है, कोई दूसरी शैक्षणिक रिपोर्ट नहीं। यह मूल P1 रिपोर्ट पर आधारित है, प्रमुख चित्रों और सारणियों को सुरक्षित रखता है, और हर महत्वपूर्ण चरण पर “इसका अर्थ क्या है” जैसी सार्वजनिक व्याख्या जोड़ता है। |
यह लेख केवल उन निष्कर्षों की व्याख्या करता है जो P1 ने अपने निर्धारित डेटा-समूह, पैरामीटर खाता-बही और सांख्यिकीय प्रोटोकॉल के अंतर्गत निकाले: आकाशगंगा घूर्णन वक्रों (RC) और galaxy–galaxy weak lensing (GGL) की संयुक्त जाँच में EFT का औसत गुरुत्वीय प्रतिक्रिया मॉडल इस लेख में परखे गए न्यूनतम DM_RAZOR baseline से स्पष्ट रूप से आगे है। |
यह लेख P1 को “डार्क मैटर को गिराने” वाले निष्कर्ष के रूप में नहीं पढ़ता। P1 P श्रृंखला प्रयोगों का केवल पहला कदम है; यह EFT के “औसत गुरुत्वीय आधार-स्तर” नामक एक अवलोकनीय स्तर को परखता है, संपूर्ण EFT सिद्धांत को नहीं। |
0|पहले 5 मिनट में P1 को समझें: यह काम आखिर कर क्या रहा है?
P1 को आप “अलग-अलग प्रोबों के बीच पारस्परिक सत्यापन” का प्रयोग समझ सकते हैं। यह केवल यह नहीं पूछता कि कोई मॉडल एक डेटा-समूह को फिट कर सकता है या नहीं; बल्कि यह दो बिल्कुल भिन्न गुरुत्वीय रीडिंग को एक ही ऑडिट-मंच पर रखता है: घूर्णन वक्र (RC) आकाशगंगा-डिस्क की गतिकी पढ़ते हैं, जबकि galaxy–galaxy weak lensing (GGL) बड़े पैमाने पर प्रक्षेपित गुरुत्वीय प्रतिक्रिया पढ़ती है।
- RC “स्पीडोमीटर” जैसा है: यह बताता है कि आकाशगंगा-डिस्क में गैस और तारे अलग-अलग त्रिज्याओं पर कितनी तेज़ी से घूमते हैं।
- GGL “वज़न-कांटे” जैसा है: यह देखता है कि अग्रभूमि की आकाशगंगाएँ पृष्ठभूमि के प्रकाश को कितना हल्का मोड़ती हैं, और उससे आकाशगंगा के आसपास बड़े पैमाने पर औसत गुरुत्व/द्रव्यमान वितरण का अनुमान लगाता है।
- P1 का मुख्य प्रश्न है: क्या वही मॉडल पहले RC से नियम सीख सकता है और फिर उन नियमों को GGL पर स्थानांतरित करने पर भी सुसंगत रह सकता है?
P1 का सबसे मुख्य वाक्य |
P1 तुलना की कसौटी को “अलग से फिट अच्छा है या नहीं” से उठाकर “क्या क्रॉस-प्रोब क्लोज़र बनता है” तक ले जाता है। सही मैपिंग में अच्छा प्रदर्शन और मैपिंग बिगाड़ने पर संकेत का ढहना—यही बताता है कि मॉडल ने संभवतः RC और GGL के बीच साझा गुरुत्वीय संरचना पकड़ी है। |
सारणी 0|P1 के मुख्य आँकड़े और सामान्य पाठक के लिए उनका अर्थ
सूचक | P1 / P1A में पढ़ने का तरीका | सामान्य पाठक इसे कैसे समझें |
संयुक्त फिट ΔlogL_total | मुख्य-पाठ तुलना में EFT, DM_RAZOR के सापेक्ष 1155–1337 है | दोनों डेटा-समूहों को मिलाकर कुल स्कोर का अंतर; जितना बड़ा, समग्र व्याख्या उतनी बेहतर। |
क्लोज़र शक्ति ΔlogL_closure | मुख्य-पाठ तुलना में EFT 172–281 है, DM_RAZOR 127 है | केवल RC inference के बाद GGL की भविष्यवाणी करने की क्षमता; जितना बड़ा, उतना अधिक “क्रॉस-प्रोब self-consistent”। |
नकारात्मक नियंत्रण shuffle | RC-bin→GGL-bin को shuffle करने के बाद EFT का क्लोज़र संकेत 6–23 तक घटता है | यदि सही correspondence टूट जाए, तो लाभ गायब होना चाहिए; जितना स्पष्ट गायब हो, pseudo-signal को उतना बेहतर बाहर किया जा सकता है। |
P1A बहु-DM दबाव परीक्षण | DM 7+1 + DM_STD, और EFT_BIN को नियंत्रण के रूप में सुरक्षित रखा गया | P1A केवल न्यूनतम DM_RAZOR नहीं देखता; यह कई निम्न-आयामी, ऑडिट-योग्य DM enhancement branches को एक ही क्लोज़र प्रोटोकॉल में रखता है। |
1|P1 क्यों करना ज़रूरी है: आज आकाशगंगा-पैमाने की ब्रह्माण्डविद्या कहाँ अटकी है?
आकाशगंगा-पैमाने की समस्या लंबे समय से कठिन इसलिए है कि “अतिरिक्त गुरुत्व/द्रव्यमान की आवश्यकता” केवल घूर्णन वक्रों का मामला नहीं है। अनेक अवलोकन बताते हैं कि आकाशगंगाओं में दिखने वाले बैरिऑनिक पदार्थ और वास्तविक गतिकीय/लेंसिंग रीडिंग के बीच गहरा संबंध है। डार्क-मैटर मार्ग के लिए इसका अर्थ है कि डार्क हैलो, बैरिऑनिक फीडबैक, आकाशगंगा-निर्माण इतिहास और अवलोकनीय प्रणालीगत त्रुटियों को अत्यंत सूक्ष्मता से समन्वित करना होगा; गैर-डार्क-मैटर गुरुत्व मार्ग के लिए इसका अर्थ है कि मॉडल केवल RC पर सुंदर नहीं दिख सकता—उसे कमज़ोर लेंसिंग, जनसंख्या-स्तरीय स्केलिंग नियमों और नकारात्मक नियंत्रणों में भी टिकना होगा।
यही P1 की प्रेरणा है: यह “डार्क मैटर गलत है” या “EFT निश्चित ही सही है” से शुरू नहीं करता, बल्कि एक जाँच योग्य दावे को सुनवाई के लिए रखता है—क्या EFT में औसत गुरुत्वीय प्रतिक्रिया RC→GGL के क्रॉस-प्रोब क्लोज़र में पुनरुत्पाद्य और स्थानांतरित होने वाला संकेत छोड़ती है?
बाहरी साहित्य पृष्ठभूमि: RC+GGL की यह खिड़की महत्वपूर्ण क्यों है? |
McGaugh, Lelli और Schombert (2016) द्वारा प्रस्तावित radial acceleration relation (RAR) दिखाता है कि घूर्णन वक्रों से ट्रेस की गई observed acceleration और बैरिऑनिक पदार्थ से predicted acceleration के बीच मजबूत संबंध है, और scatter छोटा है। इससे “बैरिऑन–गुरुत्व प्रतिक्रिया coupling” आकाशगंगा-पैमाने के सिद्धांतों के लिए अनिवार्य प्रश्न बन जाता है। |
Brouwer et al. (2021) ने KiDS-1000 weak lensing से RAR को कम acceleration और बड़े radii तक बढ़ाया, और MOND, Verlinde emergent gravity तथा LambdaCDM models की तुलना की; साथ ही उन्होंने बताया कि early-/late-type galaxy differences, gas halos और galaxy–halo connection अब भी प्रमुख व्याख्यात्मक प्रश्न हैं। |
Mistele et al. (2024) ने weak lensing से isolated galaxies की circular velocity curves उलटकर निकालीं और रिपोर्ट किया कि वे सैकड़ों kpc से लगभग 1 Mpc तक स्पष्ट रूप से नहीं गिरतीं तथा BTFR से संगत हैं। इससे पता चलता है कि weak lensing आकाशगंगा-पैमाने की गुरुत्वीय प्रतिक्रिया को जाँचने की महत्वपूर्ण बाहरी रीडिंग बन रही है। |
इसलिए P1 का मूल्य इस बात में नहीं है कि यह “RC और GGL को साथ रखने वाला पहला काम” है, बल्कि इस बात में है कि यह उन्हें एक ऑडिट-योग्य प्रोटोकॉल में रखता है: स्थिर मैपिंग, पैरामीटर खाता-बही, RC-only→GGL क्लोज़र, shuffle नकारात्मक नियंत्रण और P1A बहु-DM दबाव परीक्षण।
2|P1 में EFT का क्या अर्थ है? यह Effective Field Theory नहीं है
यहाँ EFT का अर्थ Energy Filament Theory—ऊर्जा फिलामेंट सिद्धांत—है, भौतिकी में प्रचलित Effective Field Theory नहीं। P1 तकनीकी रिपोर्ट में EFT का प्रयोग बहुत संयमित है: यह संपूर्ण अंतिम सिद्धांत के रूप में प्रतिस्पर्धा नहीं करता, बल्कि पहले एक अवलोकनीय, फिट-योग्य और खंडनीय “औसत गुरुत्वीय प्रतिक्रिया” पैरामीटरीकरण में संकुचित किया गया है।
सरल भाषा में: P1 अतिरिक्त गुरुत्व के सभी सूक्ष्म स्रोतों पर अभी चर्चा नहीं करता, और न ही पूरी EFT को एक ही बार में सिद्ध करने की कोशिश करता है। वह केवल एक संकरा और कठोर प्रश्न पूछता है—यदि आकाशगंगा-पैमाने पर कोई औसत अतिरिक्त गुरुत्वीय प्रतिक्रिया मौजूद है, तो क्या वह पहले RC को समझा सकती है और फिर GGL की भविष्यवाणी में स्थानांतरित हो सकती है?
P1 EFT के किस हिस्से को पकड़ता है? |
P1 “औसत गुरुत्वीय आधार-स्तर” (mean gravity floor) को पकड़ता है: सांख्यिकीय रूप से स्थिर, नमूनों के पार स्थानांतरित होने वाला औसत योगदान। |
P1 फिलहाल “शोर आधार-स्तर” (stochastic / noise floor) को नहीं संभालता: यानी वे random terms, individual differences या अतिरिक्त scatter जो अधिक सूक्ष्म fluctuation processes से आ सकते हैं। |
P1 पूर्ण सूक्ष्म तंत्र, abundance, lifetime या वैश्विक cosmological constraints पर भी चर्चा नहीं करता। यह P श्रृंखला प्रयोगों का पहला कदम है, अंतिम फैसला नहीं। |
3|P1 श्रृंखला योजना: पहला कदम “औसत आधार-स्तर” से क्यों शुरू होता है?
P श्रृंखला को EFT की अवलोकनीय खोज-योजना समझा जा सकता है। यह सभी दावों को एक साथ नहीं फैलाती; पहले उस हिस्से को अलग निकालती है जिसे सार्वजनिक डेटा से सबसे आसानी से जाँचा जा सकता है। P1 की रणनीति पहले औसत पद को परखना है: यदि औसत गुरुत्वीय प्रतिक्रिया RC→GGL में क्लोज़र ही नहीं बना सकती, तो अधिक जटिल शोर-पदों या सूक्ष्म तंत्रों पर आगे चर्चा का प्रवेश-द्वार कमज़ोर होगा।
सारणी 1|P श्रृंखला की स्तरबद्ध स्थिति
स्तर | पूछा जाने वाला प्रश्न | P1 में स्थान |
P1 | क्या औसत गुरुत्वीय प्रतिक्रिया RC→GGL में क्लोज़र बना सकती है? | वर्तमान रिपोर्ट का मुख्य प्रश्न |
P1A | DM पक्ष को थोड़ा मजबूत करने पर भी निष्कर्ष स्थिर रहते हैं? | परिशिष्ट B: DM 7+1 + DM_STD pressure test |
आगे की P श्रृंखला | क्या इसे अधिक डेटा, अधिक प्रोब और अधिक जटिल systematic errors तक बढ़ाया जा सकता है? | आगामी कार्य-दिशा |
गहरे स्तर के प्रश्न | औसत पद, शोर पद और सूक्ष्म तंत्र कैसे जुड़ते हैं? | P1 के निष्कर्षों की सीमा में नहीं |
4|डेटा क्या है? RC और GGL अलग-अलग क्या बताते हैं?
4.1 घूर्णन वक्र RC: आकाशगंगा-डिस्क का “घूर्णन-माप”
घूर्णन वक्र यह दर्ज करते हैं कि आकाशगंगा के केंद्र से अलग-अलग त्रिज्याओं पर गैस और तारे केंद्र के चारों ओर कितनी तेज़ी से घूमते हैं। जितना तेज़ घूर्णन, उस त्रिज्या पर उतना अधिक अभिकेंद्रीय बल चाहिए—अर्थात अधिक प्रभावी गुरुत्व। P1 SPARC डेटाबेस का उपयोग करता है; पूर्व-प्रसंस्करण के बाद इसमें 104 आकाशगंगाएँ, 2295 वेग डेटा-बिंदु और 20 RC-bin शामिल हैं।
4.2 कमज़ोर लेंसिंग GGL: बड़े पैमाने का “गुरुत्वीय तराज़ू”
galaxy–galaxy weak lensing मापती है कि अग्रभूमि की आकाशगंगाएँ पृष्ठभूमि आकाशगंगाओं के प्रकाश को किस हद तक हल्का मोड़ती हैं। यह बड़े, हैलो-पैमाने पर प्रक्षेपित गुरुत्वीय प्रतिक्रिया से संबंधित है और आकाशगंगा गैस-गतिकी के सूक्ष्म विवरणों पर निर्भर नहीं करता। P1 KiDS-1000 / Brouwer et al. 2021 के सार्वजनिक GGL डेटा का उपयोग करता है: 4 stellar-mass bins, प्रत्येक में 15 त्रिज्या बिंदु, कुल 60 डेटा-बिंदु, और पूर्ण covariance के साथ।
4.3 स्थिर मैपिंग: 20 RC-bin → 4 GGL-bin इतना महत्वपूर्ण क्यों है?
P1 20 RC-bin को 4 GGL-bin से एक स्थिर नियम द्वारा जोड़ता है: प्रत्येक GGL-bin पाँच RC-bin से संबंधित है और आकाशगंगा-संख्या भारों से औसत निकाला जाता है। यह मैपिंग सभी मॉडलों के लिए अपरिवर्तित रहती है; क्लोज़र परीक्षण और निष्पक्ष तुलना के लिए यह कठोर बाधा है।
मैपिंग को बाद में क्यों नहीं बदला जा सकता? |
यदि बाद में यह चुनने दिया जाए कि “कौन-से RC-bin किन GGL-bin से मेल खाते हैं”, तो मॉडल correspondence को समायोजित करके क्लोज़र बना सकता है। P1 पहले से 20→4 मैपिंग लॉक करता है और shuffle negative control से उसे जानबूझकर तोड़ता है, ताकि यह जाँचा जा सके कि क्लोज़र संकेत सचमुच भौतिक रूप से उचित correspondence पर निर्भर है या नहीं। |
5|मॉडल और पद्धति: P1 असल में “क्या तुलना” कर रहा है?
5.1 EFT पक्ष: निम्न-आयामी औसत गुरुत्वीय प्रतिक्रिया
EFT पक्ष औसत गुरुत्वीय प्रतिक्रिया का वर्णन करने के लिए एक निम्न-आयामी अतिरिक्त वेग-पद का उपयोग करता है: अतिरिक्त पद का आकार निरायामी kernel function f(r/ℓ) से नियंत्रित होता है, जहाँ ℓ वैश्विक पैमाना है, और आयाम RC-bin के अनुसार दिया जाता है। अलग-अलग kernel functions अलग आरंभिक ढाल, संक्रमण गति और दीर्घ-पुच्छ को दर्शाते हैं; इनका उपयोग robustness pressure tests में होता है।
5.2 DM पक्ष: मुख्य-पाठ तुलना और परिशिष्ट P1A को अलग-अलग पढ़ना चाहिए
मुख्य-पाठ की प्रधान तुलना में DM_RAZOR एक न्यूनतम, ऑडिट-योग्य NFW baseline है: c–M संबंध स्थिर है; इसमें halo-to-halo scatter, adiabatic contraction, feedback core, अस्फेरिकता या पर्यावरणीय पद शामिल नहीं हैं। इस डिज़ाइन का लाभ है कि स्वतंत्रता-डिग्रियाँ नियंत्रित हैं और परिणाम पुनरुत्पाद्य हैं; कमी यह है कि यह सभी LambdaCDM या सभी डार्क-मैटर हैलो मॉडलों का प्रतिनिधित्व नहीं करता।
इसीलिए परिशिष्ट B (P1A) में DM पक्ष को “standardized pressure tests” के समूह में बदला गया है: साझा मैपिंग और क्लोज़र प्रोटोकॉल को बदले बिना, SCAT, AC, FB, HIER_CMSCAT, CORE1P, lensing m और संयुक्त baseline DM_STD जैसे निम्न-आयामी enhancement branches क्रमशः जोड़े जाते हैं, और EFT_BIN को तुलना के लिए रखा जाता है। P1A को ऐसे समझें: तुलना केवल एक न्यूनतम DM baseline से नहीं है; बल्कि सामान्य और ऑडिट-योग्य DM तंत्रों के समूह को उसी “क्लोज़र मापदंड” पर परखा गया है।
इस लेख में अपनाया गया सटीक निष्कर्ष-वाक्य |
मुख्य पाठ: प्रधान तुलना में EFT श्रृंखला न्यूनतम DM_RAZOR से स्पष्ट रूप से बेहतर है। |
परिशिष्ट B / P1A: कई निम्न-आयामी, ऑडिट-योग्य DM enhancement branches और DM_STD pressure test के अंतर्गत DM की कुछ संयुक्त फिटिंग सुधर सकती है, पर क्लोज़र शक्ति EFT_BIN के लाभ को समाप्त नहीं करती। |
इसलिए सबसे सावधान अभिव्यक्ति यह है: P1/P1A के डेटा, मैपिंग, पैरामीटर खाता-बही और क्लोज़र प्रोटोकॉल की सीमा में EFT की औसत गुरुत्वीय प्रतिक्रिया अधिक मजबूत cross-data consistency दिखाती है; इसका अर्थ सभी डार्क-मैटर मॉडलों को बाहर करना नहीं है। |
5.3 क्लोज़र परीक्षण: P1 की सबसे महत्वपूर्ण प्रयोगात्मक व्याकरण
1. केवल RC से फिट करें और RC-only posterior samples का एक समूह प्राप्त करें।
2. GGL से दोबारा पैरामीटर ट्यून करने की अनुमति नहीं; सीधे RC posterior से GGL की भविष्यवाणी करें।
3. पूर्ण covariance के साथ सही मैपिंग के अंतर्गत GGL prediction score logL_true की गणना करें।
4. RC-bin→GGL-bin correspondence को यादृच्छिक रूप से permute करें और नकारात्मक नियंत्रण logL_perm की गणना करें।
5. दोनों का अंतर लेकर क्लोज़र शक्ति प्राप्त करें: ΔlogL_closure = <logL_true> − <logL_perm>।
सरल उपमा |
क्लोज़र परीक्षण एक cross-exam retest जैसा है: मॉडल पहले RC परीक्षा-कक्ष में नियम सीखता है, फिर GGL परीक्षा-कक्ष में उत्तर देता है। यदि उसने सच में साझा नियम सीखा है, केवल स्थानीय तरकीब नहीं, तो परीक्षा-कक्ष बदलने के बाद भी उसे अच्छा उत्तर देना चाहिए; और यदि परीक्षा-कक्षों की correspondence जानबूझकर बिगाड़ दी जाए, तो लाभ गायब होना चाहिए। |
5.4 तकनीकी सारणियाँ पढ़ने से पहले: पहले चार प्रवेश-बिंदु पकड़ें
सारणी 5.4|अगली क्षैतिज तकनीकी सारणियों को पढ़ने का मार्ग
प्रवेश | क्या देखें | क्यों महत्वपूर्ण है |
सारणी S1a | RC+GGL संयुक्त फिट का कुल स्कोर | इसका उत्तर देता है: “दोनों डेटा साथ देखने पर किसकी समग्र व्याख्या मजबूत है।” |
सारणी S1b | क्लोज़र शक्ति, shuffle और robustness scans | इसका उत्तर देता है: “RC में सीखी बात GGL में स्थानांतरित हो सकती है या नहीं।” |
सारणी B0 | P1A में अनेक DM enhancement branches की परिभाषाएँ | P1 को “केवल न्यूनतम DM_RAZOR से तुलना” तक घटाने से बचाता है। |
सारणी B1 | P1A का क्लोज़र और संयुक्त scoreboard | जाँचता है कि DM को मजबूत करने के बाद क्लोज़र लाभ समाप्त होता है या नहीं। |
लेआउट टिप्पणी |
अगले पृष्ठ से landscape pages का उपयोग मूल रिपोर्ट की चौड़ी सारणियों को पूरा सुरक्षित रखने के लिए है, ताकि कॉलम हटाने या उन्हें अपठनीय रूप से संपीड़ित करने की आवश्यकता न पड़े। मुख्य-पाठ व्याख्या पहले ही सामान्य पाठक के लिए पढ़ने का तरीका दे चुकी है; landscape technical tables उन पाठकों के लिए हैं जिन्हें संख्याएँ और model branches जाँचना हैं। |
चित्र 0.1|एक चित्र में P1 की क्लोज़र-परीक्षण प्रक्रिया
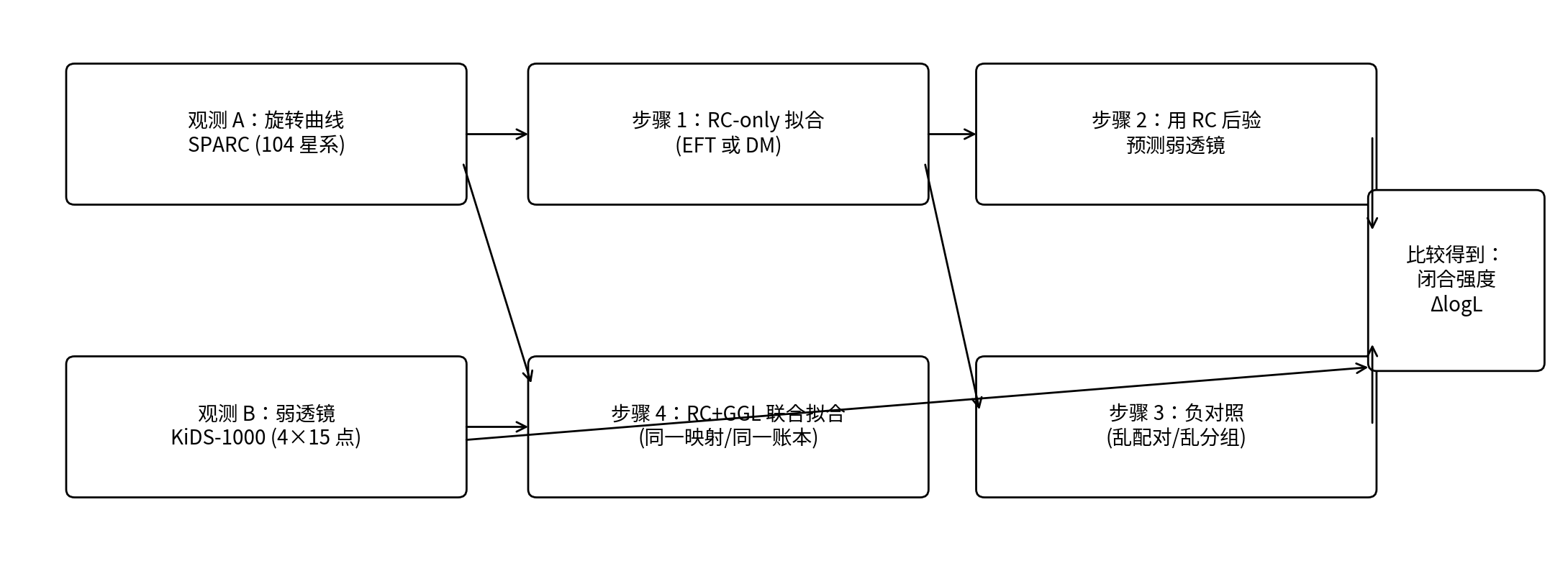
व्याख्या: ऊपरी शृंखला “क्लोज़र परीक्षण” है (केवल RC से फिट → RC posterior से GGL की भविष्यवाणी); निचली शृंखला “संयुक्त फिट” है (RC+GGL को साथ स्कोर किया जाता है)। दाईं ओर वास्तविक मैपिंग की shuffled मैपिंग से तुलना करके क्लोज़र शक्ति ΔlogL निकाली जाती है।
6|मुख्य तकनीकी सारणियाँ: मूल रिपोर्ट की मुख्य सारणियाँ और P1A सारणियाँ
सारणी S1a|संयुक्त फिट के मुख्य तुलना सूचकांक (RC+GGL, Strict; मूल रिपोर्ट से सुरक्षित)
मॉडल (workspace) | W kernel | k | संयुक्त logL_total (best) | ΔlogL_total बनाम DM | AICc | BIC |
DM_RAZOR | none | 20 | -16927.763 | 0.0 | 33895.885 | 34010.811 |
EFT_BIN | none | 21 | -15590.552 | 1337.21 | 31223.501 | 31344.155 |
EFT_WEXP | exponential | 21 | -15668.83 | 1258.932 | 31380.057 | 31500.711 |
EFT_WYUK | yukawa | 21 | -15772.936 | 1154.827 | 31588.268 | 31708.922 |
EFT_WPOW | powerlaw_tail | 21 | -15633.321 | 1294.442 | 31309.038 | 31429.692 |
सारणी S1b|क्लोज़र और मजबूती सूचकांक (Strict; मूल रिपोर्ट से सुरक्षित)
मॉडल (workspace) | क्लोज़र ΔlogL (true-perm) | नकारात्मक नियंत्रण shuffle के बाद ΔlogL | σ_int scan में ΔlogL सीमा | R_min scan में ΔlogL सीमा | cov-shrink scan में ΔlogL सीमा |
DM_RAZOR | 126.678 | 22.725 | — | — | — |
EFT_BIN | 231.611 | 14.984 | 459–1548 | 1243–1289 | 1337–1351 |
EFT_WEXP | 171.977 | 6.04 | 408–1471 | 1169–1207 | 1259–1277 |
EFT_WYUK | 179.808 | 14.688 | 380–1341 | 1065–1099 | 1155–1166 |
EFT_WPOW | 280.513 | 6.672 | 457–1500 | 1203–1247 | 1294–1308 |
सारणी B0|P1A में DM enhancement branches की परिभाषाएँ (मूल रिपोर्ट के परिशिष्ट B से सुरक्षित)
Workspace | dm_model | नया पैरामीटर (≤1) | भौतिक प्रेरणा (मुख्य) | कार्यान्वयन सिद्धांत (ऑडिट-अनुकूल) |
|---|---|---|---|---|
DM_RAZOR | NFW (fixed c–M, no scatter) | — | न्यूनतम, ऑडिट-योग्य LambdaCDM halo baseline; EFT के साथ कठोर comparison के लिए | साझा मैपिंग स्थिर; पैरामीटर खाता-बही कठोर; baseline के रूप में केवल सापेक्ष comparison के लिए |
DM_RAZOR_SCAT | NFW + c–M scatter(legacy) | σ_logc | c–M relation में scatter है; इसे one-parameter log-normal scatter से approximate किया जाता है | ≤1 नया पैरामीटर; अब भी shared mapping; closure gain को acceptance criterion बनाया गया |
DM_RAZOR_AC | NFW + Adiabatic Contraction(legacy) | α_AC | बैरिऑन infall halo adiabatic contraction ला सकता है; इसे one-parameter strength से approximate किया जाता है | ≤1 नया पैरामीटर; मैपिंग नहीं बदली; AICc/BIC बदलाव और closure gain रिपोर्ट किए जाते हैं |
DM_RAZOR_FB | NFW + feedback core(legacy) | log r_core | feedback भीतर के क्षेत्र में core बना सकता है; इसे one-parameter core scale से approximate किया जाता है | ≤1 नया पैरामीटर; closure/negative control समान प्रोटोकॉल; RC-only सुधार को अकेला लक्ष्य नहीं बनाया गया |
DM_HIER_CMSCAT | Hierarchical c–M scatter + prior | σ_logc(hier) | अधिक मानक hierarchical c_i∼logN(c(M_i),σ_logc); RC और GGL संयुक्त posterior दोनों को प्रभावित करता है | स्पष्ट prior; latent c_i marginalized; फिर भी निम्न-आयामी और ऑडिट-योग्य |
DM_CORE1P | 1‑parameter core proxy (coreNFW/DC14‑inspired) | log r_core | baryonic feedback के मुख्य प्रभाव को one-parameter core proxy से दर्शाया गया, ताकि high-dimensional star-formation details से बचा जा सके | मानक साहित्य उद्धृत; ≤1 नया पैरामीटर; closure test से बंधा हुआ |
DM_RAZOR_M | NFW + lensing shear‑calibration nuisance | m_shear(GGL) | weak-lensing पक्ष की प्रमुख systematic error को effective parameter से absorb करता है, ताकि “systematic error को physics समझने” का जोखिम घटे | nuisance स्पष्ट रूप से accounted; RC को reverse influence की अनुमति नहीं; परिणामों में closure robustness मुख्य है |
DM_STD | Standardized DM baseline (HIER_CMSCAT + CORE1P + m) | σ_logc + log r_core (+ m_shear) | तीन सबसे सामान्य objections को एक अब भी निम्न-आयामी standardized baseline में साथ शामिल करता है | parameter ledger + information criteria साथ रिपोर्ट; closure मुख्य metric; सबसे मजबूत DM-defense control के रूप में |
सारणी B1|P1A scoreboard (जितना बड़ा उतना बेहतर; मूल रिपोर्ट के परिशिष्ट B से सुरक्षित)
मॉडल शाखा (workspace) | Δk | RC-only best logL_RC (Δ) | क्लोज़र शक्ति ΔlogL_closure (Δ) | Joint best logL_total (Δ) |
DM_RAZOR | 0 | -15702.654 (+0.000) | 122.205 (+0.000) | -27347.068 (+0.000) |
DM_RAZOR_SCAT | 1 | -15702.294 (+0.361) | 121.236 (-0.969) | -23153.311 (+4193.758) |
DM_RAZOR_AC | 1 | -15703.689 (-1.035) | 121.531 (-0.674) | -23982.557 (+3364.511) |
DM_RAZOR_FB | 1 | -15496.046 (+206.609) | 129.454 (+7.249) | -27478.531 (-131.463) |
DM_HIER_CMSCAT | 1 | -15702.644 (+0.010) | 121.978 (-0.227) | -23153.160 (+4193.908) |
DM_CORE1P | 1 | -15723.158 (-20.504) | 122.056 (-0.149) | -27336.258 (+10.810) |
DM_RAZOR_M | 0 (+m) | -15702.654 (+0.000) | 122.205 (+0.000) | -27340.451 (+6.617) |
DM_STD | 2 (+m) | -15832.203 (-129.549) | 105.690 (-16.515) | -22984.445 (+4362.623) |
EFT_BIN | 1 | -14631.537 (+1071.117) | 204.620 (+82.415) | -19001.142 (+8345.926) |
सारणी B1 (P1A scoreboard) कैसे पढ़ें |
• Δk: नए degrees of freedom (जितना बड़ा, मॉडल उतना जटिल; जटिल होना बेहतर होना नहीं है)। • दो कॉलम पर ध्यान दें: closure strength ΔlogL_closure(Δ) (जितना बड़ा उतना अधिक “transfer self-consistent”) और Joint best logL_total(Δ) (संयुक्त फिट का कुल स्कोर)। • कोष्ठक में (Δ), DM_RAZOR के सापेक्ष अंतर दिखाता है, ताकि सीधी तुलना हो सके। |
• यह सारणी मुख्यतः पूछती है: जब DM baseline को “युक्तिसंगत रूप से मजबूत” किया जाता है, तो क्या closure advantage गायब हो जाता है? • पढ़ने की टिप: DM_STD का संयुक्त स्कोर स्पष्ट रूप से सुधरता है, लेकिन closure strength उलटे घटती है; EFT_BIN closure strength में अब भी अधिक रहता है। |
एक-वाक्य सार: निम्न-आयामी, ऑडिट-योग्य DM enhancements की इस सीमा में संयुक्त फिट को सुधारना अपने-आप अधिक मजबूत closure नहीं देता; closure (transferability) अब भी मुख्य कसौटी है। |
7|मुख्य परिणाम कैसे पढ़ें?
7.1 संयुक्त फिट: दोनों डेटा-समूह साथ देखने पर EFT की मुख्य तुलना का स्कोर अधिक है
सारणी S1a और चित्र S4 दिखाते हैं कि समान डेटा, समान साझा मैपिंग और लगभग समान पैरामीटर पैमाने पर EFT श्रृंखला का संयुक्त ΔlogL_total, DM_RAZOR की तुलना में 1155–1337 है। सामान्य पाठक इसे ऐसे समझ सकते हैं: RC और GGL को एक ही scoring rule में साथ रखने पर EFT मुख्य-तुलना मॉडल का कुल स्कोर अधिक है।
7.2 क्लोज़र परीक्षण: P1 सबसे अधिक “स्थानांतरण-क्षमता” पर ज़ोर देता है
उच्च क्लोज़र शक्ति का अर्थ है कि मॉडल केवल RC से निकाले गए पैरामीटरों के आधार पर, GGL को फिर से देखे बिना, GGL की बेहतर भविष्यवाणी कर सकता है। P1 रिपोर्ट में EFT का ΔlogL_closure 172–281 है, जबकि DM_RAZOR का 127 है। यह परिणाम “दोनों अलग-अलग ठीक फिट होते हैं” से अधिक महत्वपूर्ण है, क्योंकि यह दूसरी डेटा-श्रृंखला पर मॉडल की स्वतंत्रता को सीमित करता है।
7.3 नकारात्मक नियंत्रण: “संकेत का ढहना” उलटे अच्छी बात क्यों है?
जब P1 ने RC-bin→GGL-bin की grouping correspondence को यादृच्छिक रूप से shuffle किया, तो EFT का क्लोज़र संकेत 6–23 के स्तर तक गिर गया। सामान्य पाठक के लिए यह “anti-cheating” चरण जैसा है: यदि क्लोज़र लाभ केवल कोड, इकाइयों, covariance या फिटिंग की संयोगजन्य वजह से होता, तो गलत correspondence पर भी लाभ रह सकता था। वास्तविक परिणाम में लाभ ढहता है, जिससे पता चलता है कि वह सही मैपिंग पर निर्भर है।
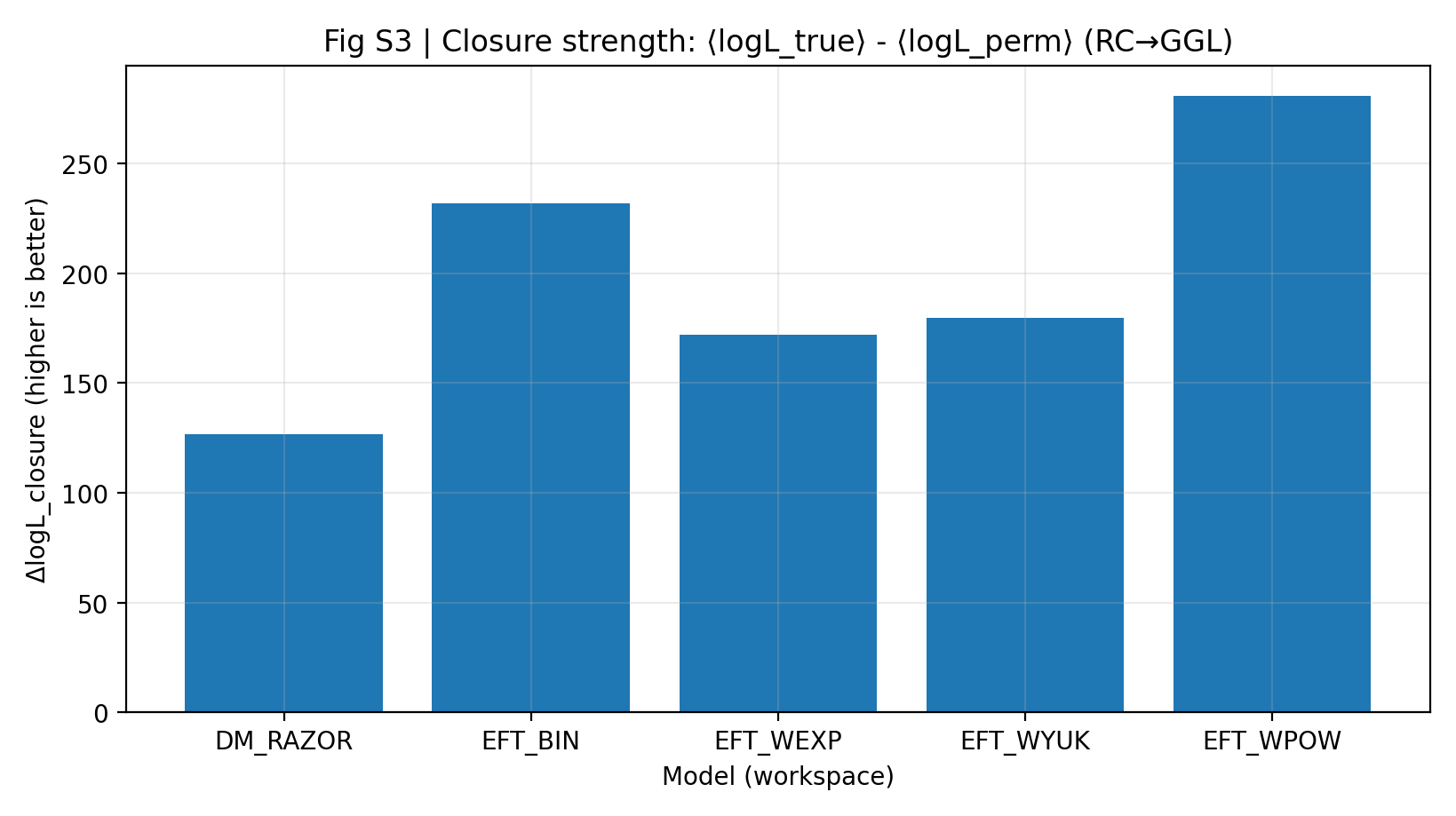
चित्र S3|क्लोज़र शक्ति (जितनी बड़ी उतनी बेहतर): RC-only → GGL भविष्यवाणी का औसत log-likelihood लाभ।
इस चित्र को कैसे पढ़ें |
यह चित्र P1 का केंद्र है। स्तंभ जितना ऊँचा, मॉडल ने RC से जो सूचना सीखी है वह GGL में उतनी अधिक स्थानांतरित हो सकती है। |
EFT श्रृंखला समग्र रूप से DM_RAZOR से ऊपर है, जिससे “पहले RC सीखो, फिर GGL की भविष्यवाणी करो” प्रयोग में EFT का cross-probe closure अधिक मजबूत दिखता है। |
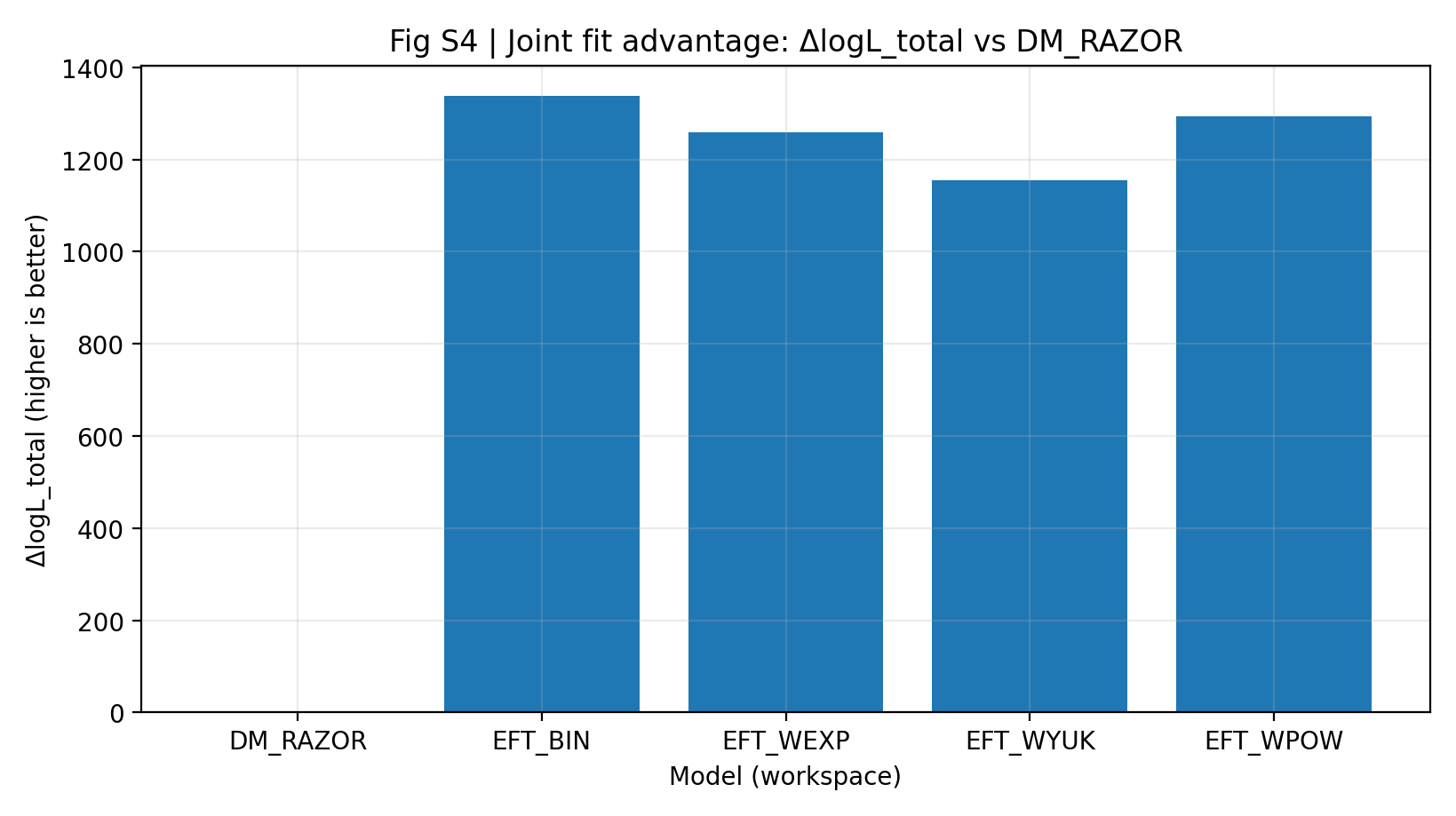
चित्र S4|संयुक्त फिट लाभ (जितना बड़ा उतना बेहतर): RC+GGL का best logL_total, DM_RAZOR के सापेक्ष।
इस चित्र को कैसे पढ़ें |
यह चित्र RC और GGL को मिलाने के बाद का कुल स्कोर देखता है। |
EFT श्रृंखला के सभी मान 0 से स्पष्ट रूप से ऊपर हैं, जिससे पता चलता है कि मुख्य तुलना में EFT का लाभ किसी एक स्थानीय बिंदु की घटना नहीं, बल्कि संयुक्त विश्लेषण का समग्र प्रदर्शन है। |
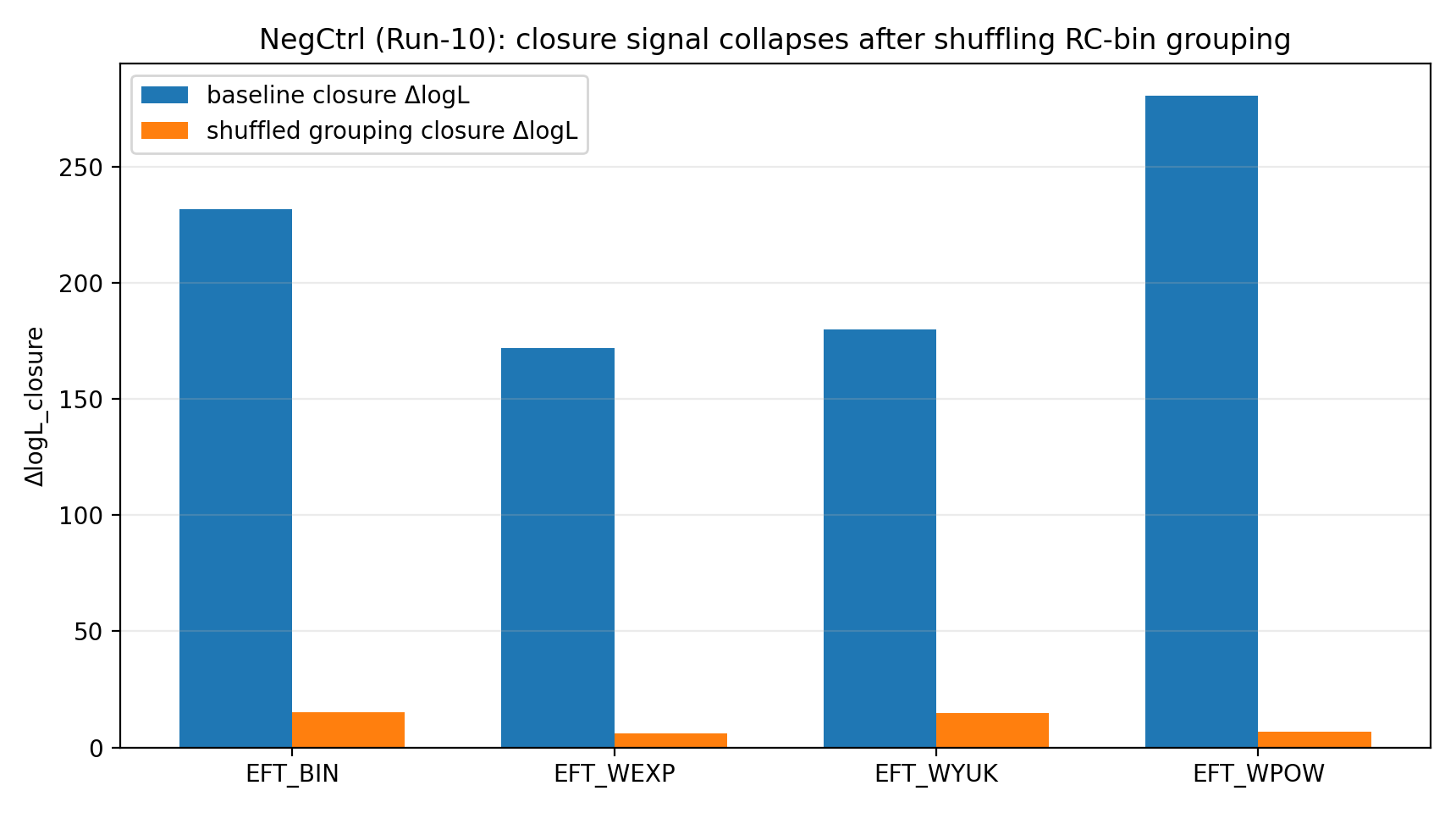
चित्र R1|नकारात्मक नियंत्रण: grouping shuffle के बाद क्लोज़र संकेत स्पष्ट रूप से घटता है।
इस चित्र को कैसे पढ़ें |
यह चित्र दिखाता है कि सही RC↔GGL binning relationship बिगड़ते ही closure signal स्पष्ट रूप से घटता है। |
इससे P1 परिणाम किसी arbitrary mapping से मिलने वाले numerical coincidence की जगह cross-data mapping में वास्तविक consistency जैसे दिखते हैं। |
8|मजबूती और नियंत्रण: P1 “सिर्फ़ पैरामीटर ट्यून करके अच्छा दिखना” कैसे टालता है?
किसी तकनीकी रिपोर्ट पर सबसे आसान शंका होती है: क्या लाभ किसी noise setting, किसी केंद्रीय-क्षेत्र डेटा-खंड, किसी covariance treatment या overfitting से आया है? P1 इस प्रश्न का उत्तर कई pressure tests से देता है।
सारणी 2|P1 की मजबूती और नकारात्मक नियंत्रण कैसे पढ़ें
परीक्षण | यह कौन-सी शंका हटाना चाहता है | पढ़ने का तरीका |
σ_int scan | यदि RC में अतिरिक्त अज्ञात scatter है, तो निष्कर्ष स्थिर रहते हैं? | RC errors को ढीला करने के बाद EFT ranking और advantage scale स्थिर रहते हैं। |
R_min scan | यदि आकाशगंगा के केंद्रीय क्षेत्र पर पूरी तरह भरोसा न हो, तो निष्कर्ष स्थिर हैं? | केंद्रीय क्षेत्र को काटने के बाद भी EFT सकारात्मक लाभ बनाए रखता है। |
cov-shrink scan | यदि GGL covariance estimate में uncertainty है, तो निष्कर्ष स्थिर हैं? | covariance को diagonal matrix की ओर shrink करने पर लाभ insensitive रहता है। |
ablation ladder | क्या EFT अनावश्यक complexity से hard fitting कर रहा है? | पूर्ण EFT_BIN information criteria में आवश्यक दिखता है। |
LOO leave-out prediction | क्या मॉडल केवल देखा हुआ डेटा ही समझाता है? | GGL bin छोड़ने के बाद भी मजबूत generalization performance दिखता है। |
RC-bin shuffle | क्या closure वास्तविक मैपिंग से आता है? | grouping बिगाड़ने के बाद closure घटता है, जो mapping dependence का समर्थन करता है। |
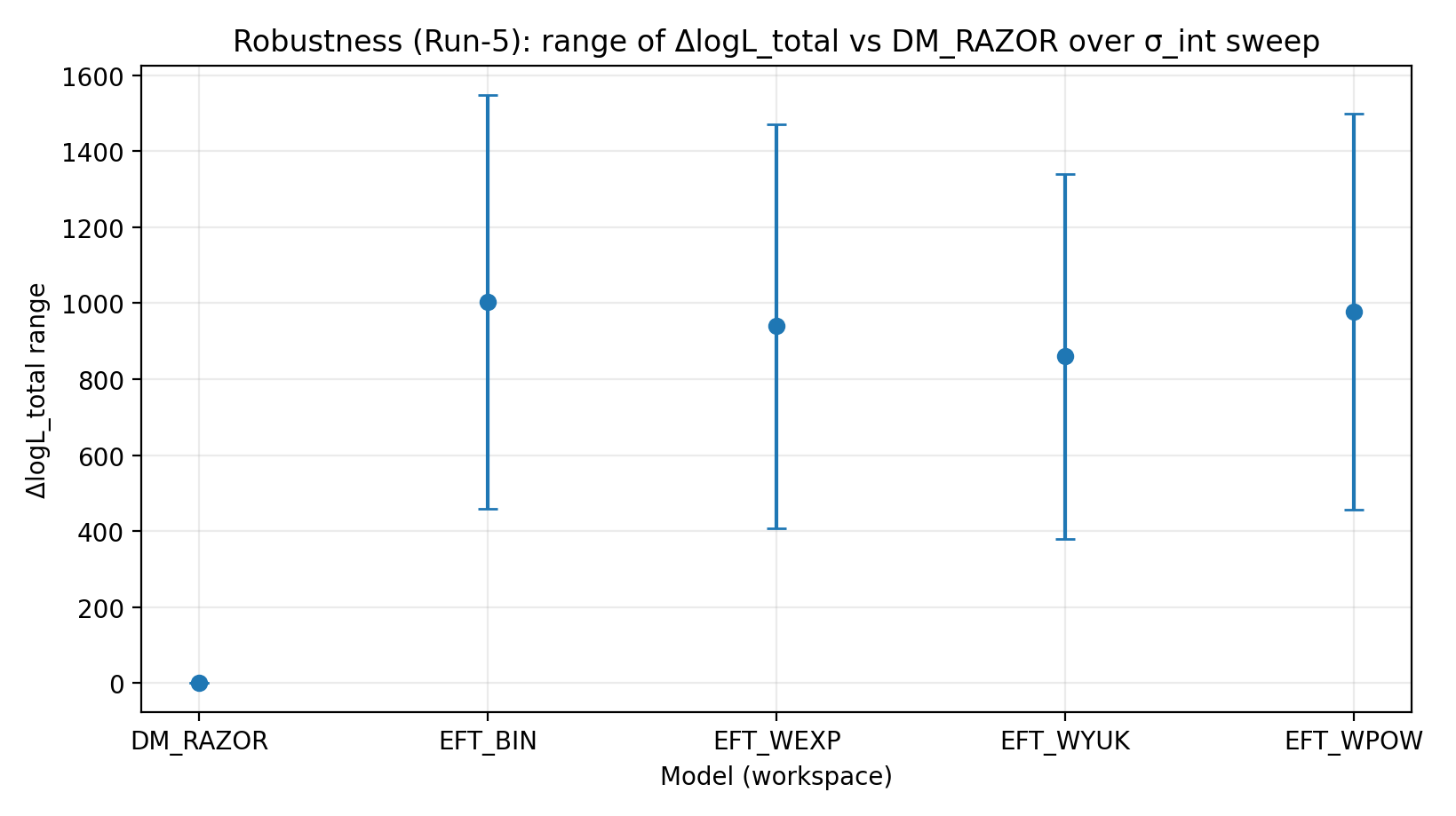
चित्र R2|σ_int scan के अंतर्गत ΔlogL_total की सीमा (जितनी बड़ी उतनी बेहतर)।
इस चित्र को कैसे पढ़ें |
जाँचता है कि RC intrinsic scatter setting बदलने के बाद भी EFT की बढ़त रहती है या नहीं। |
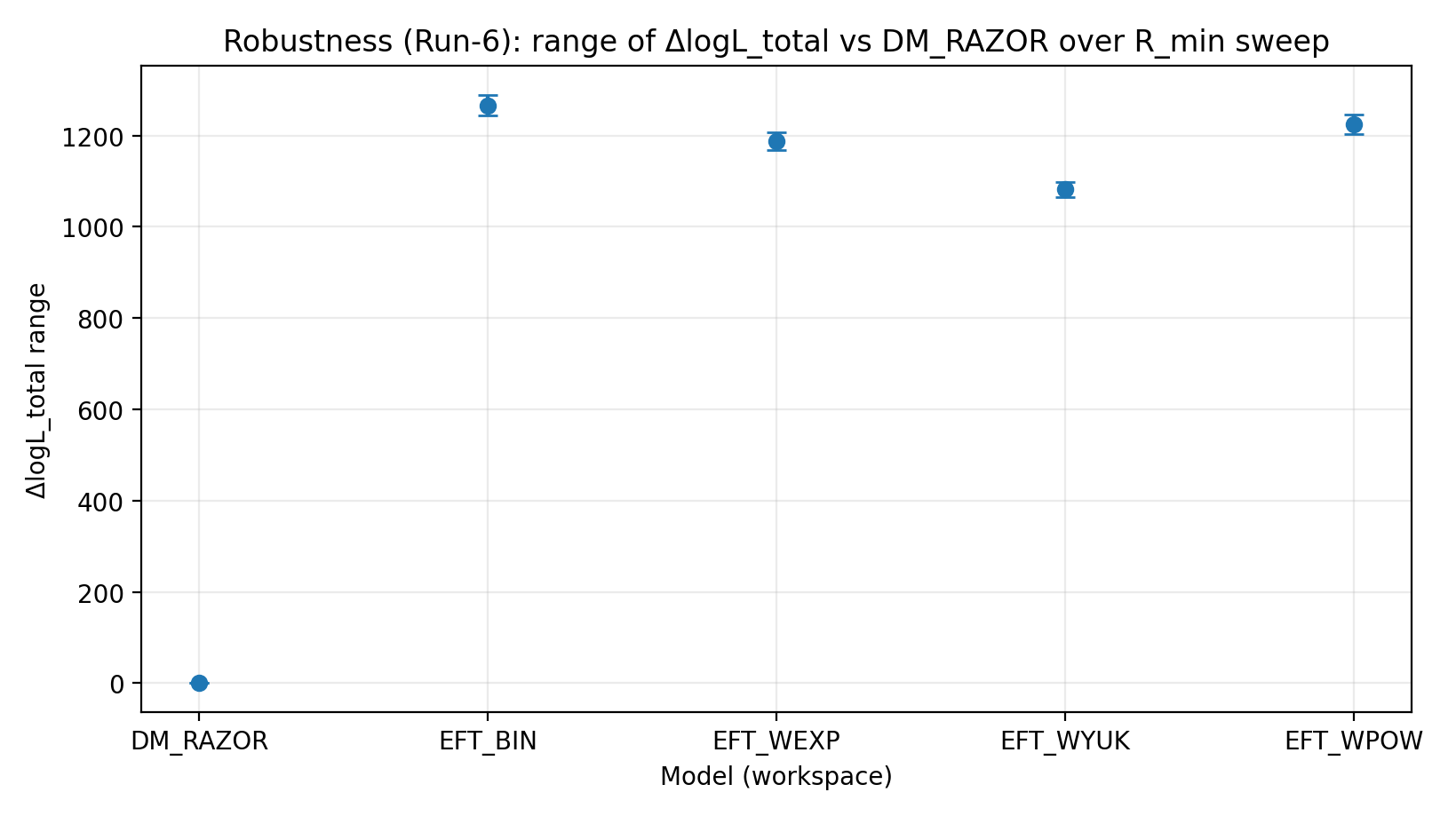
चित्र R3|R_min scan के अंतर्गत ΔlogL_total की सीमा (जितनी बड़ी उतनी बेहतर)।
इस चित्र को कैसे पढ़ें |
जाँचता है कि जटिल केंद्रीय क्षेत्र काटने के बाद भी EFT का लाभ स्थिर रहता है या नहीं। |
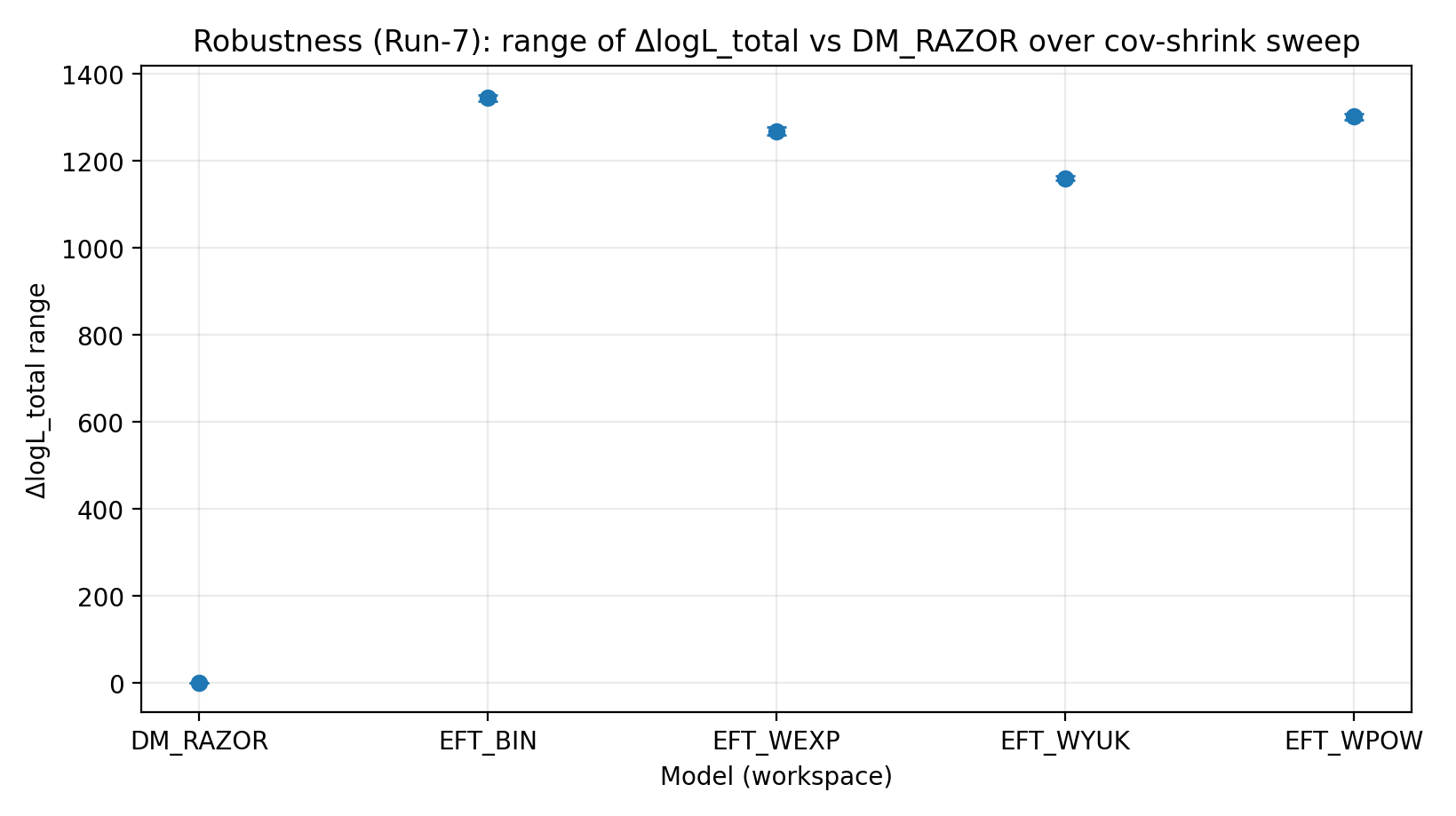
चित्र R4|cov-shrink scan के अंतर्गत ΔlogL_total की सीमा (जितनी बड़ी उतनी बेहतर)।
इस चित्र को कैसे पढ़ें |
जाँचता है कि weak-lensing covariance treatment बदलने पर ranking sensitive है या नहीं। |
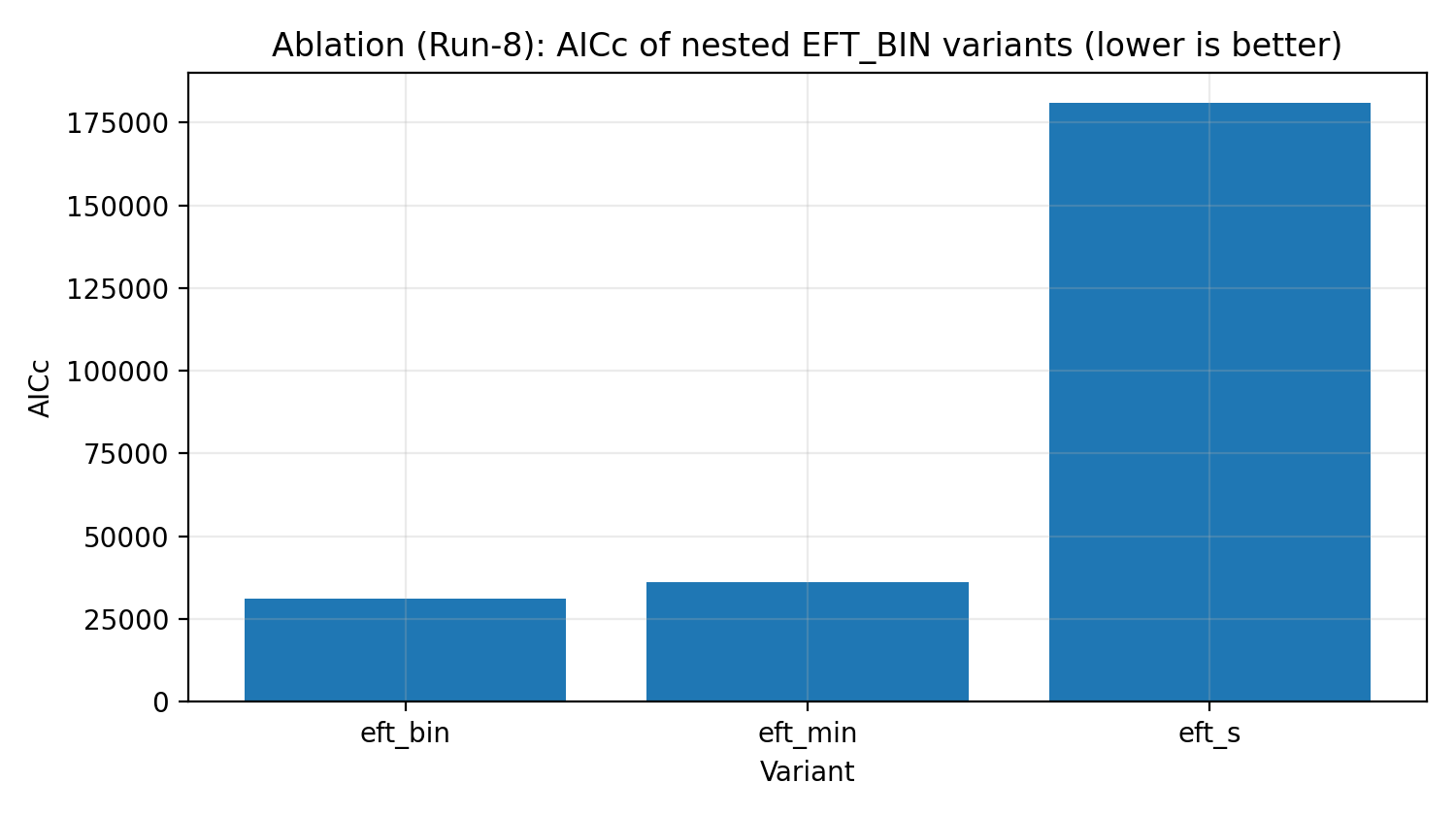
चित्र R5|EFT_BIN की ablation ladder (AICc, जितना छोटा उतना बेहतर)।
इस चित्र को कैसे पढ़ें |
जाँचता है कि पूर्ण EFT_BIN डेटा-व्याख्या में आवश्यक है या केवल बेकार पैरामीटर जोड़ना नहीं। |
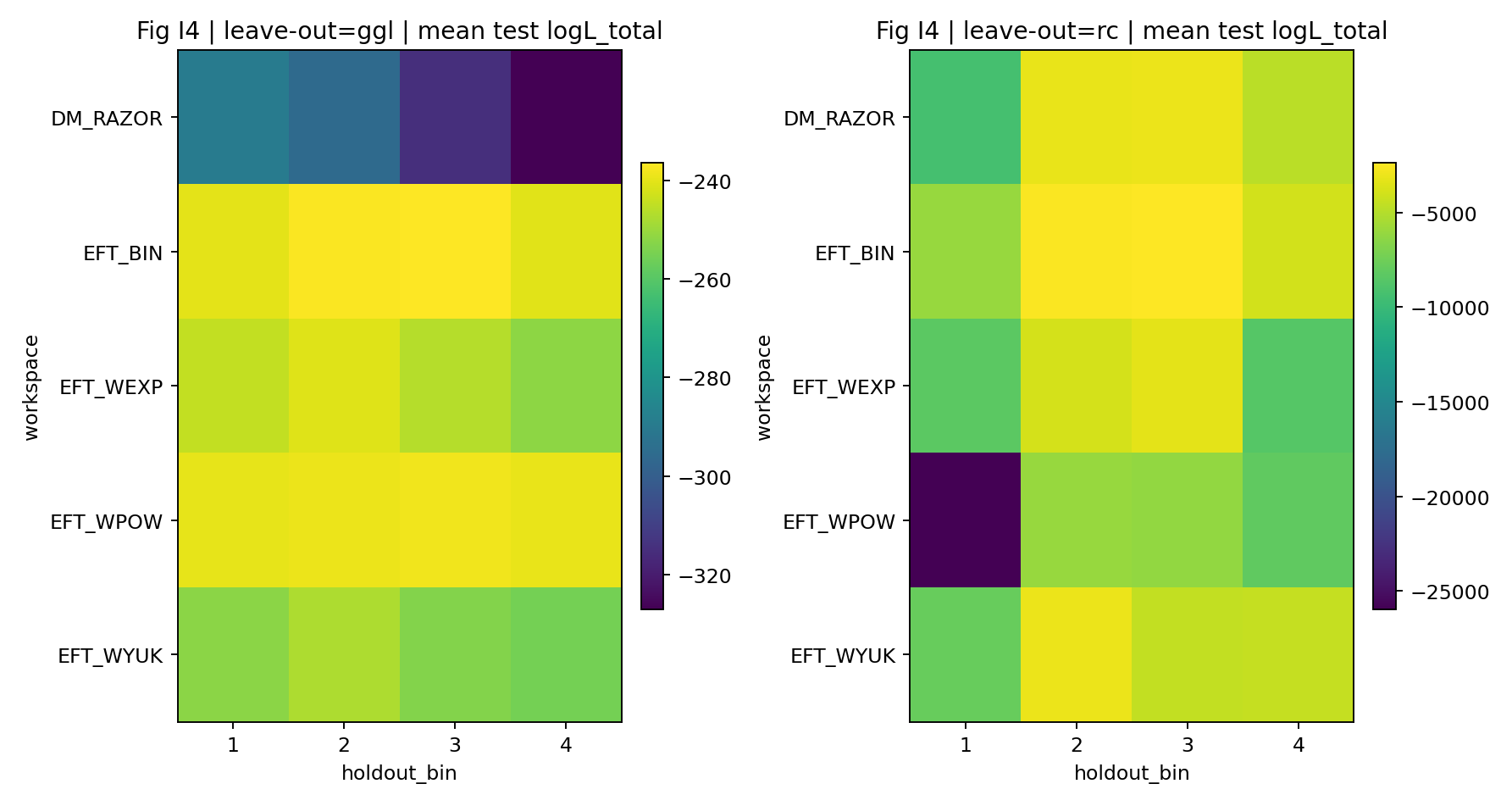
चित्र R6|LOO: छोड़े गए bin की log-likelihood वितरण।
इस चित्र को कैसे पढ़ें |
जाँचता है कि unseen GGL bin पर भी मॉडल में predictive performance रहता है या नहीं। |
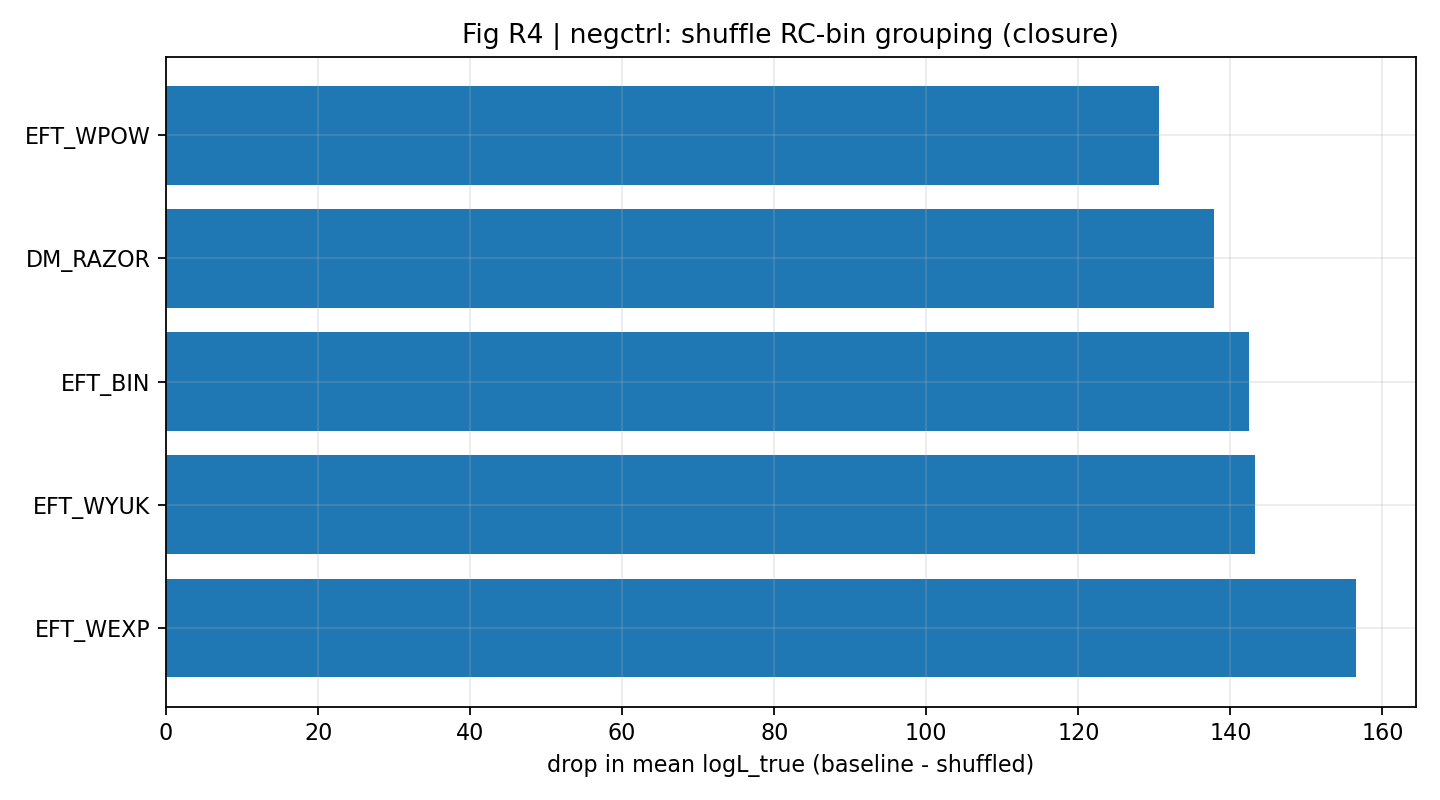
चित्र R7|नकारात्मक नियंत्रण: shuffled मैपिंग से क्लोज़र mean logL_true स्पष्ट रूप से घटता है।
इस चित्र को कैसे पढ़ें |
mean logL_true के दृष्टिकोण से आगे दिखाता है कि closure सही cross-data mapping पर निर्भर है। |
9|P1A: “परिशिष्ट में अनेक DM मॉडल” एक महत्वपूर्ण संशोधन क्यों है?
इस अनुभाग का प्रश्न “क्या EFT ने केवल एक न्यूनतम DM_RAZOR को हराया?” नहीं है। प्रश्न यह है: जब हम निम्न-आयामी, पुनरुत्पाद्य और साफ़ पैरामीटर-खाता सीमा के भीतर DM baseline को मजबूत करते हैं (P1A), तो क्या क्लोज़र परीक्षण और संयुक्त फिट के निष्कर्ष बदल जाते हैं? दूसरे शब्दों में, P1A का लक्ष्य “आपने बस बहुत कमजोर DM baseline चुना” वाली शंका को कम करना और चर्चा को इस प्रश्न तक ले जाना है कि “ऑडिट-योग्य DM enhancements के समूह में क्लोज़र प्रदर्शन में अंतर अब भी रहता है या नहीं।”
P1A का डिज़ाइन LambdaCDM हैलो मॉडलिंग की हर संभावना को समाप्त करने का दावा नहीं करता, और न ही DM पक्ष को उच्च-आयामी, अनऑडिटेबल fitter बनाता है। यह निम्न-आयामी, पुनरुत्पाद्य और स्पष्ट पैरामीटर-खाते वाले enhancements चुनता है: concentration scatter, adiabatic contraction, feedback core, hierarchical c–M scatter prior, single-parameter core proxy, weak-lensing shear-calibration nuisance, और संयुक्त DM_STD।
P1A को पढ़ने का मुख्य तरीका |
तीन legacy branches में केवल feedback/core ने closure strength में छोटी net improvement दी; SCAT और AC ने net closure improvement नहीं दी। |
DM_HIER_CMSCAT, DM_RAZOR_M और DM_CORE1P का closure strength पर प्रभाव बहुत छोटा है या वे स्पष्ट net improvement नहीं दिखाते। |
DM_STD joint logL को स्पष्ट रूप से सुधार सकता है, पर closure strength घटती है; इससे संकेत मिलता है कि यह मुख्यतः संयुक्त फिट की flexibility बढ़ाता है, RC→GGL transfer-prediction power नहीं। |
P1A सारणी B1 में EFT_BIN अब भी अधिक closure strength और संयुक्त-fit लाभ रखता है; इसलिए P1 का मुख्य दावा “केवल न्यूनतम DM_RAZOR को हराया” तक सीमित नहीं किया जाना चाहिए। |
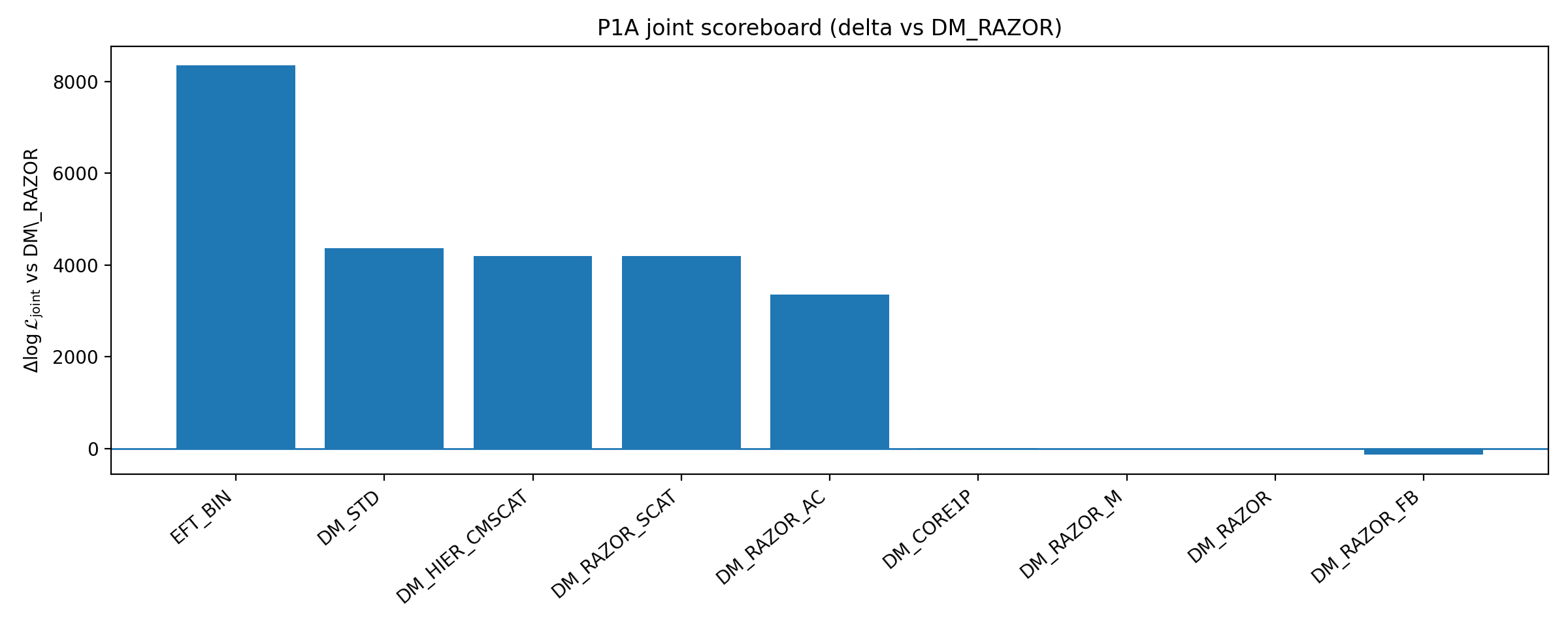
चित्र B1|P1A scoreboard: baseline के सापेक्ष क्लोज़र और संयुक्त ΔlogL (जितना बड़ा उतना बेहतर)।
इस चित्र को कैसे पढ़ें |
यह चित्र baseline के सापेक्ष कई DM enhancement branches का प्रदर्शन दिखाता है। |
इसका अर्थ “सभी DM को बाहर करना” नहीं है, बल्कि यह दिखाना है कि P1A द्वारा चुने गए निम्न-आयामी, ऑडिट-योग्य DM enhancements की सीमा में DM को मजबूत करने से EFT_BIN का closure advantage समाप्त नहीं हुआ। |
10|P1 प्रयोग का महत्व: यह काम करने लायक क्यों है?
10.1 पद्धतिगत महत्व: “क्रॉस-प्रोब क्लोज़र” को “single-probe fitting” से ऊँचा स्थान देना
आकाशगंगा-पैमाने के सिद्धांत अक्सर इस विवाद में फँस जाते हैं कि कोई मॉडल किसी घूर्णन-वक्र सेट को फिट कर सकता है या नहीं। P1 प्रश्न को एक स्तर ऊपर उठाता है: RC से सीखे गए पैरामीटर क्या GGL को फिर से ट्यून किए बिना कमज़ोर लेंसिंग की भविष्यवाणी कर सकते हैं? इससे P1 “फिटिंग प्रतियोगिता” से “स्थानांतरण-पूर्वानुमान परीक्षण” बन जाता है।
10.2 पारदर्शिता का महत्व: पुनरावलोकनीय शृंखला को परिणाम का हिस्सा बनाना
P1 का एक महत्वपूर्ण योगदान यह है कि यह डेटा, सारणियाँ/चित्र, run labels, नकारात्मक नियंत्रण, पुनरुत्पादन पैकेज और audit chain को साथ प्रकाशित करता है। समर्थकों और आलोचकों दोनों के लिए यह महत्वपूर्ण है: चर्चा नारेबाज़ी पर नहीं, बल्कि उसी सार्वजनिक डेटा, उसी मैपिंग, उसी scripts और उन्हीं सूचकों पर लौट सकती है।
10.3 भौतिक महत्व: यह “गैर-डार्क-मैटर गुरुत्व” दिशा को एक कठोर दबाव-परीक्षण देता है
गैर-डार्क-मैटर गुरुत्व दिशा में कई मॉडल घूर्णन वक्रों या RAR के किसी हिस्से को समझा सकते हैं; पर अधिक कठिन है कमज़ोर लेंसिंग रीडिंग से भी गुजरना और नकारात्मक नियंत्रण के अंतर्गत दिखाना कि संकेत सही मैपिंग पर निर्भर है। P1 का महत्व यह है कि उसने EFT की औसत गुरुत्वीय प्रतिक्रिया को “बाहरी परीक्षा” जैसे प्रोटोकॉल में रखा: RC प्रशिक्षण-मैदान है, GGL स्थानांतरण-मैदान है, और shuffle anti-cheating मैदान है।
10.4 क्या यह “गैर-डार्क-मैटर गुरुत्व क्षेत्र” का महत्वपूर्ण प्रयोग है?
सावधानी से कहा जाए तो: यदि P1 की data processing, reproduction package और closure protocol बाहरी पुनर्परीक्षण में भी टिकते हैं, तो इसे गैर-डार्क-मैटर गुरुत्व / संशोधित गुरुत्व दिशा में गंभीरता से लेने योग्य RC+GGL क्लोज़र प्रयोग माना जा सकता है। इसका महत्व “डार्क मैटर को गिरा दिया” जैसी पंक्ति में नहीं, बल्कि इस बात में है कि यह पुनरुत्पाद्य, चुनौती-योग्य और विस्तार-योग्य क्रॉस-प्रोब कसौटी देता है।
क्या पहले से समान रूप से उच्च RC+GGL prediction-closure framework मौजूद है? |
संबंधित frameworks और observational traditions पहले से हैं: MOND/RAR बड़ी संख्या में rotation-curve phenomena को अच्छी तरह व्यवस्थित करता है; KiDS-1000 weak-lensing RAR work ने MOND, Verlinde emergent gravity और LambdaCDM models की तुलना भी की है। LambdaCDM भी galaxy–halo connection, gas halos और feedback modeling से कुछ weak-lensing/dynamical phenomena समझा सकता है। |
लेकिन P1 का सटीक दावा यह नहीं है कि “दुनिया में कोई अन्य framework RC+GGL को नहीं समझा सकता”; दावा यह है कि P1 द्वारा सार्वजनिक की गई fixed mapping, RC-only→GGL closure, shuffle negative control, parameter ledger और P1A multi-DM pressure-test protocol के अंतर्गत EFT ने अधिक मजबूत closure performance रिपोर्ट किया। |
दूसरे शब्दों में, P1 का बाहरी जाँच के लिए सबसे मूल्यवान हिस्सा इसकी ठोस, पुनरुत्पाद्य comparison protocol है। आगे यह देखना बहुत महत्वपूर्ण होगा कि क्या MOND/RAR, LambdaCDM/HOD, hydrodynamical simulation या अन्य modified-gravity frameworks उसी protocol के अंतर्गत समान या अधिक closure scores प्राप्त कर सकते हैं। |
11|P1 से क्या निष्कर्ष निकाले जा सकते हैं? क्या नहीं?
सारणी 3|P1 की निष्कर्ष-सीमाएँ
निकाला जा सकता है | P1 के RC+GGL डेटा, fixed mapping और मुख्य comparison protocol के अंतर्गत EFT श्रृंखला में न्यूनतम DM_RAZOR की तुलना में अधिक संयुक्त फिट और closure strength है। |
निकाला जा सकता है | P1A के निम्न-आयामी, ऑडिट-योग्य DM enhancement range में कई DM enhancements ने EFT_BIN का closure advantage समाप्त नहीं किया। |
निकाला जा सकता है | shuffle negative control दिखाता है कि closure signal सही cross-data mapping पर निर्भर है, arbitrary mapping से नहीं मिलता। |
नहीं निकाला जा सकता | यह नहीं कहा जा सकता कि P1 ने सभी डार्क-मैटर मॉडलों को गिरा दिया है। P1A अब भी non-sphericity, environmental dependence, complex galaxy–halo connections, high-dimensional feedback या full cosmological simulations को exhaust नहीं करता। |
नहीं निकाला जा सकता | यह नहीं कहा जा सकता कि पूर्ण EFT सिद्धांत first principles से सिद्ध हो गया है। P1 केवल औसत गुरुत्वीय प्रतिक्रिया के phenomenological layer को जाँचता है। |
नहीं निकाला जा सकता | यह नहीं कहा जा सकता कि सभी systematic errors हट चुकी हैं। P1 केवल सूचीबद्ध pressure tests और audit range के भीतर robustness evidence देता है। |
12|अक्सर पूछे जाने वाले प्रश्न: सामान्य पाठक के सबसे सहज सवाल
Q1: क्या यह कह रहा है कि “डार्क मैटर मौजूद नहीं है”?
नहीं। P1 के निष्कर्षों को इस लेख के डेटा, प्रोटोकॉल और comparison models की सीमा में ही पढ़ना चाहिए। P1A न्यूनतम DM_RAZOR से आगे जाता है, लेकिन फिर भी सभी संभावित डार्क-मैटर मॉडलों का प्रतिनिधित्व नहीं करता।
Q2: क्या यह कह रहा है कि “EFT सिद्ध हो चुकी है”?
यह भी नहीं। P1 EFT को औसत गुरुत्वीय प्रतिक्रिया पैरामीटरीकरण के रूप में जाँचता है और दिखाता है कि RC→GGL क्लोज़र में उसका प्रदर्शन अधिक मजबूत है; सूक्ष्म तंत्र और पूर्ण सिद्धांत P1 के निष्कर्ष नहीं हैं।
Q3: सीधे significance σ value क्यों नहीं दी गई?
P1 unified likelihood score, information criteria और closure differences का उपयोग करता है। ΔlogL उसी scoring rule के अंतर्गत सापेक्ष लाभ है; यह किसी एकल σ value के बराबर नहीं है।
Q4: RC-bin→GGL-bin को shuffle क्यों करना ज़रूरी है?
यह नकारात्मक नियंत्रण है। वास्तविक क्रॉस-प्रोब संकेत सही मैपिंग पर निर्भर होना चाहिए; यदि shuffle के बाद भी वह उतना ही मजबूत रहे, तो यह implementation bias या सांख्यिकीय pseudo-signal का संकेत हो सकता है।
Q5: P1 का अगला सबसे ज़रूरी कदम क्या होना चाहिए?
उसी प्रोटोकॉल को अधिक डेटा, अधिक DM controls, अधिक जटिल systematic errors और अधिक modified-gravity frameworks तक फैलाना; विशेष रूप से बाहरी टीमों को उसी क्लोज़र metric के अंतर्गत पुनर्परीक्षण करने योग्य बनाना।
13|छोटा शब्दकोश
सारणी 4|छोटा शब्दकोश
शब्द | एक-वाक्य व्याख्या |
घूर्णन वक्र (RC) | आकाशगंगा-डिस्क में radius–rotation-speed संबंध, जिससे डिस्क के भीतर effective gravity का अनुमान लगाया जाता है। |
कमज़ोर लेंसिंग (GGL) | पृष्ठभूमि आकाशगंगाओं के आकार की सांख्यिकीय विकृति से अग्रभूमि आकाशगंगाओं के आसपास औसत gravity/mass distribution मापना। |
क्लोज़र परीक्षण | RC posterior से GGL की भविष्यवाणी करना और shuffled mapping के negative control से तुलना करना। |
नकारात्मक नियंत्रण | मुख्य संरचना को जानबूझकर तोड़ना और देखना कि संकेत गायब होता है या नहीं; pseudo-signal हटाने के लिए। |
NFW halo | cold dark matter models में प्रचलित dark-matter halo density profile। |
c–M संबंध | dark-matter halo concentration c और mass M का संबंध; scatter की अनुमति model flexibility को प्रभावित करती है। |
DM_STD | P1A में अनेक निम्न-आयामी DM enhancements और lensing nuisance को जोड़ने वाली standardized DM pressure-test branch। |
ΔlogL | एक ही scoring rule के अंतर्गत दो मॉडलों का log-likelihood difference; positive value का अर्थ है कि पहला बेहतर है। |
covariance | data points के बीच correlations का matrix description; weak-lensing data में सामान्यतः पूर्ण covariance का उपयोग करना पड़ता है। |
14|सुझाया गया पठन मार्ग और उद्धरण प्रविष्टियाँ
1. पहले इस लेख के अनुभाग 0–2 पढ़ें, ताकि P1 का समस्या-बोध और P1 में EFT की संयमित स्थिति स्पष्ट हो जाए।
2. फिर चित्र S3, चित्र S4 और सारणी S1a/S1b देखें, ताकि क्लोज़र शक्ति, संयुक्त फिट और नकारात्मक नियंत्रण समझ में आएँ।
3. यदि चिंता है कि “DM baseline बहुत कमजोर तो नहीं”, तो सीधे अनुभाग 9 और सारणी B1 / चित्र B1 देखें।
4. तकनीकी पुनरावलोकन के लिए P1 technical report v1.1, Tables & Figures Supplement और full_fit_runpack पर लौटें।
मुख्य अभिलेख प्रवेश |
P1 तकनीकी रिपोर्ट (release-level, Concept DOI): 10.5281/zenodo.18526334 |
P1 पूर्ण reproduction package (Concept DOI): 10.5281/zenodo.18526286 |
EFT structured knowledge base (वैकल्पिक, Concept DOI): 10.5281/zenodo.18853200 |
लाइसेंस नोट: technical report CC BY-NC-ND 4.0 के अंतर्गत है; full reproduction package CC BY 4.0 के अंतर्गत है (technical report और Zenodo archive को आधिकारिक मानें)। |
15|संदर्भ और बाहरी पृष्ठभूमि
McGaugh, S. S., Lelli, F., & Schombert, J. M. (2016). The Radial Acceleration Relation in Rotationally Supported Galaxies. Physical Review Letters, 117, 201101. DOI: 10.1103/PhysRevLett.117.201101.
Famaey, B., & McGaugh, S. S. (2012). Modified Newtonian Dynamics (MOND): Observational Phenomenology and Relativistic Extensions. Living Reviews in Relativity, 15, 10. DOI: 10.12942/lrr-2012-10.
Brouwer, M. M., Oman, K. A., Valentijn, E. A., et al. (2021). The weak lensing radial acceleration relation: Constraining modified gravity and cold dark matter theories with KiDS-1000. Astronomy & Astrophysics, 650, A113. DOI: 10.1051/0004-6361/202040108.
Mistele, T., McGaugh, S., Lelli, F., Schombert, J., & Li, P. (2024). Indefinitely Flat Circular Velocities and the Baryonic Tully-Fisher Relation from Weak Lensing. The Astrophysical Journal Letters, 969, L3 / arXiv:2406.09685.
Bullock, J. S., & Boylan-Kolchin, M. (2017). Small-Scale Challenges to the LambdaCDM Paradigm. Annual Review of Astronomy and Astrophysics, 55, 343–387. DOI: 10.1146/annurev-astro-091916-055313.
Lelli, F., McGaugh, S. S., & Schombert, J. M. (2016). SPARC: Mass Models for 175 Disk Galaxies with Spitzer Photometry and Accurate Rotation Curves. The Astronomical Journal, 152, 157. DOI: 10.3847/0004-6256/152/6/157.
Navarro, J. F., Frenk, C. S., & White, S. D. M. (1997). A Universal Density Profile from Hierarchical Clustering. Astrophysical Journal, 490, 493.
Dutton, A. A., & Macciò, A. V. (2014). Cold dark matter haloes in the Planck era: evolution of structural parameters for NFW haloes. Monthly Notices of the Royal Astronomical Society, 441, 3359–3374.